

2026年4月9日、GTO Wizardの公式Xからこのようなポストが投稿されました。
GTO Wizardが今回公開したのは、ポーカーを用いてAI同士の強さを比較できる新たなベンチマーク環境です。
同じ条件で対戦し、その結果から実力を評価する仕組みによって、これまで曖昧だったAIの性能差が可視化されました。
本記事では、このベンチマークの仕組みと、そこから見えてきたAIの現状と今後の展望について整理します。
そもそも「GTO Wizardって何?」という方や、より深く知りたい方は、以下の記事をご覧ください。

GTO Wizardが公開した新しい
ベンチマークとは
ベンチマークとは、同じルールで性能や強さを測り、比較できるようにするための仕組みです。
つまりGTO Wizardが公開したのは、ポーカーを用いてAIの強さを測るための対戦環境です。
AI同士を同じ条件で対戦させ、その結果をもとに性能を比較できる仕組みになっています。
AIの強さを測る評価環境
これは単なる新機能ではなく、AIの能力を評価するための“共通基準”が提示されたという点に意味があります。
これまで個別に語られてきた「このAIは強い」といった評価を、同じ土俵で比較できる状態が整いました。
また、これは単なるデモや一部の検証ではなく、誰でも同じ条件で再現・比較できる形で提供されています。
ベンチマークの詳細
冒頭で説明したGTO Wizardのポストは、以下のような内容です。
- 公開API
外部からGTO Wizardの評価システムに
接続できる仕組み - ライブリーダーボード
AIの強さランキング・勝率・bb/100(利益率)をリアルタイムで表示する仕組み - AIVAT分散低減評価
運の影響を補正して、実力だけを抽出する
統計手法 - GitHubスターターコード +
完全なドキュメント
AIポーカー参加者用の“開発キット一式”
つまり、「AIポーカー評価を完全オープン化した」ということです。
審査はあるものの、誰でも自作したAIとGTO WizardのAIを対戦させ、基準に応じた評価をしてもらえます。
どのようにAIの強さを測るのか
評価の方法はシンプルで、「AI同士がポーカーで対戦し、その結果を数値化する」というものです。
同じルール・同じ条件のもとで大量のハンドをプレイし、どれだけ利益を出したかで強さを測ります。
ただし重要なのは、運の影響を極力排除している点です。
ポーカーは短期的には運の影響が大きいゲームのため、数ハンドの勝敗では実力は判断できません。
そこでこのベンチマークでは、”期待値(EV)”を基準に評価が行われます。
これにより、運のブレを排除し、“純粋な実力”だけを比較できるようになっています。
なぜポーカーで測るのか
そもそも、なぜポーカーなのでしょうか。
それは、このゲームが、AIにとって非常に特殊な構造を持っているためと考えられます。
- 相手の手札が見えない(不完全情報)
- 確率を前提とした意思決定
- ブラフや読みといった心理要素
チェスや将棋のように、すべての情報が公開されているゲームとは本質的に異なり、ポーカーでは「何が正解か分からない状況」で意思決定を続ける必要があります。
このため、単なる計算力ではなく、推測・適応・戦略といった総合的な思考力が求められます。
そのためポーカーは、AIの“思考力”を測る指標として使われているのです。
ポーカーにおけるAIの弱点
ではなぜ、すべてのモデルがGTO Wizard AIに対して安定して勝てていないのでしょうか。
主な要因は、大きく3つに整理できます。
①ゲーム特化設計ではないため
長期的な戦略が苦手
ポーカーは、数十〜数百ハンド先を見据えた長期的な戦略が求められるゲームです。
しかし、LLM系のAIはその場ごとの最適な判断には優れている一方で、長期的な期待値(EV)を最大化する意思決定は必ずしも得意ではありません。
その結果、短期的には合理的に見える判断であっても、長期的には期待値を損なうプレイが蓄積されてしまう傾向があります。
LLM系のAIとは
LLM系のAIとは、「大規模言語モデル(Large Language Model)」を基盤とするAIのことです。
大量の文章データをもとに学習し、人間のように文章の理解や生成、会話などを得意とします。
ChatGPTやClaudeなどがこれにあたります。
これについてGTO Wizardは、以下のように発信しています。

②相手の“見えない情報”の扱いが弱い
ポーカーでは、相手の手札という重要な情報が公開されていません。
そのため、プレイヤーは相手の行動や傾向から、どのようなハンドレンジを持っているかを推測する必要があります。
人間は経験則をもとに、「ブラフが多いプレイヤーである」「このアクションは強い可能性が高い」といった読みを行います。
一方でAIは、このような“レンジ推定”の精度が専用ポーカーAIに比べて劣っており、結果として相手に対する最適な戦略選択にズレが生じやすくなります。
③一貫した確率戦略の維持が苦手
ポーカーには、明確な正解が存在しません。
- 確率に基づく意思決定
- ブラフなどの例外的な行動
- 状況ごとに変化する最適解
こうした不確実性が常に存在する環境です。
AIは一般的に、「明確な正解が定義された問題」に強みを持つ構造となっています。
そのため、正解が一つに定まらない状況では、パフォーマンスが低下する傾向があります。
実際の結果──有名AIでも勝てていない
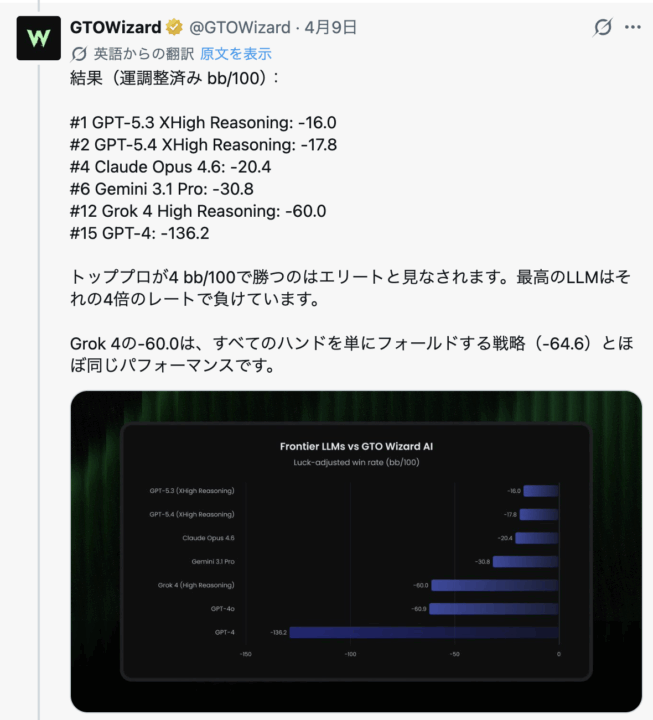
この環境で実際に検証が行われた結果、現在広く使われているAIモデルは安定して勝てておらず、AIの“限界”が可視化された結果となりました。
文章生成や会話能力では高い性能を見せるモデルでも、戦略ゲームとしてのポーカーでは苦戦しています。
これは、AIの得意分野と不得意分野の違いを示す結果と言えます。
単に「AIは強い」というイメージではなく、どの領域でどこまで通用するのかが具体的に見えるようになりました。
5,000ハンドで十分か?
AI評価に必要な試行回数は?
GTO Wizardは、有名AIに対しそれぞれ5,000ハンドのヘッズアップ・ノーリミットで対戦した結果を報告しています。
この5,000ハンドという試行回数については、世界的なポーカープレイヤーTom Dwanは自身のXで「足りないのではないか?5万〜10万回の試行回数が必要だ」と主張していました。
This is cool. 5k obviously not enough hands though, you guys should know that. Can you run a new one with 50-100k hands 🙏🏻🙏🏻 https://t.co/Wfzdmo66PM
— Tom Dwan (@TomDwan) April 10, 2026
まとめ|本質は
「AIの強さを測る基準」ができたこと
GTO Wizardの今回の発表は、単なる新機能ではなく、AIの実力を測る新たな基準を提示した点に大きな意味があります。
同じ条件で比較でき、誰でも参加できる環境が整ったことで、AIの評価はより透明で客観的なものになります。
今後は、この基準により、AIの進化はより明確に比較できるようになるでしょう。
そしてその舞台に選ばれたポーカーは、AIにとっていまだ攻略しきれていない“難題”であることも示しました。
このベンチマークを通じてAIのポーカー能力がどこまで進化していくのか、そしてポーカーという競技がどのような役割を果たしていくのか、今後の動向が注目されます。









コメント